


در این مقاله نحوه ساخت چت بات با پایتون را به صورت ساده آموزش می دهیم.
آنچه در این نوشته خواهیم داشت
چت بات یک نرم افزار دارای هوش مصنوعی در یک دستگاه مانند (Siri ، Alexa ، Google Assistant و غیره) ، اپلیکیشن و یا وبسایتی است که سعی می کند نیازهای مصرف کنندگان را ارزیابی کرده و سپس به آن ها در انجام یک کار خاص مانند یک معامله تجاری کمک کند. مثل رزرو هتل، ارسال فرم و غیره. امروزه چت بات ها در بسیاری از شرکت ها مورد استفاده قرار می گیرند تا بتواند با کاربران تعامل داشته باشند. از جمله کاربردهای چت بات در شرکت ها می توان به موارد زیر اشاره کرد:
ارائه اطلاعات پرواز
ارتباط با مشتریان و امور مالی آنها
پشتیبانی مشتری
به طور کلی دو نوع چت بات وجود دارد.
چت بات قانون محور (Rule-Based) و چت بات خودآموز(Self-Learning)
١. در مدل قانون محور ، یک ربات به سوالات بر اساس آموزش هایی که قبلا فراگرفته پاسخ می دهد. قوانین تعریف شده می توانند بسیار ساده و یا بسیار پیچیده باشند. ربات ها می توانند پرسش و پاسخ ساده ای را انجام دهند اما در مدیریت موارد پیچیده موفق نیستند.
٢. چت بات های خودآموز از برخی رویکردهای مبتنی بر ماشین لرنینگ استفاده می کنند و قطعا از چت بات های قانون محور کارآمدتر هستند. این چت بات ها به دو نوع تقسیم می شوند: مبتنی بر یازیابی و تولیدی
١-٢. در مدل مبتنی بر بازیابی، چت بات از یک سری الگوریتم های فراابتکاری به منظور انتخاب پاسخ از یک کتابخانه دارای پاسخ های از پیش تعیین شده استفاده می کند.
٢-٢ چت بات تولیدی می تواند پاسخ ها را تولید کند و همچنین همیشه به یک سوال یک پاسخ تکراری نمی دهد. هرچه تعدا پرسش و پاسخ ها بیشتر شود، چت بات هوشمندتر می شود.

پیش نیازها:
داشتن دانش کلی از کتابخانه scikit و NLTK. اما اگر در NLP تازه وارد هستید باز هم می توانید مقاله را بخوانید و سپس به منابع مراجعه کنید.
رشته تحصیلی که بر تعامل بین زبان بشر و رایانه ها تمرکز دارد به اختصار پردازش زبان طبیعی” یا NLP نامیده می شود. این رشته با علوم کامپیوتر ، هوش مصنوعی و زبان شناسی محاسباتی سروکار دارد. NLP روشی است که به وسیله آن کامپیوترها می توانند زبان انسان را هوشمندانه تر آنالیز ، درک و استخراج کنند. با استفاده از NLP توسعه دهندگان می توانند دانش خود را برای انجام کارهایی مانند خلاصه سازی خودکار، ترجمه، استخراج رابطه، تجزیه و تحلیل احساسات، تشخیص گفتار و تقسیم موضوع سازماندهی کرده و ساختار بخشند.
NLTK (ابزار زبان طبیعی) یک بستر پیشرو برای ساختن برنامه های پایتون برای کار با داده های زبان انسانی است. NLTK ابزاری فوق العاده برای آموزش و کار در زبانشناسی محاسباتی با استفاده از پایتون” و یک کتابخانه شگفت انگیز برای بازی با زبان طبیعی” معرفی شده است. پردازش زبان طبیعی با پایتون مقدمه ای عملی برای برنامه نویسی برای پردازش زبان است.
NLTK را نصب کرده و pip install nltk را اجرا کنید.
آزمایش نصب: پایتون را اجرا کرده و import nltk را تایپ کنید.
نصب بسته های NLTK:
NLTK را وارد کنید و nltk.download () را اجرا کنید. با این کار NLTK downloader را باز کرده و می توانید مدل ها را برای بارگیری انتخاب کنید. همچنین می توانید همه بسته ها را به طور همزمان دانلود کنید.
مسئله اصلی در مورد داده های متن این است که همه در قالب متن هستند. اما الگوریتم های یادگیری ماشین به نوعی از بردار ویژگی عددی احتیاج دارند. بنابراین قبل از شروع هر پروژه NLP باید آن را از قبل پردازش کنیم تا مناسب سازی شود. پیش پردازش متن اصلی شامل موارد زیر است:
تبدیل کل متن به حروف بزرگ یا حروف کوچک به گونه ای که الگوریتم با کلمات مشابه در موارد مختلف به صورت متفاوت رفتار نمی کند.
Tokenization: Tokenization (نشانه گذار) فقط اصطلاحی است که برای توصیف فرآیند تبدیل رشته های متن معمولی به لیستی از نشانه ها بکار رفته است. نشانه گذار جمله می تواند برای یافتن لیست جملات مورد استفاده قرار گیرد و از نشانه گذار کلمات برای یافتن لیست کلمات در رشته ها استفاده می شود.
پس از مرحله پردازش اولیه، باید متن را به یک بردار معنی دار (یا آرایه) از اعداد تبدیل کنیم. کوله کلمات شامل واژگان کلمات شناخته شده و معیار حضور کلمات شناخته شده است. شهود پشت کوله کلمات این است که اسناد با محتوای یکسان، مشابه هستند. همچنین ما می توانیم راجع به معنی سند از طریق مطالب آن دریابیم.
مشکل کوله کلمات در این است که کلمات پر تکرار شروع به غالب شدن در سند می کنند؛ اما ممکن است شامل محتوای اطلاعاتی (informational) نباشند. همچنین کوله کلمات به اسناد طولانی تر وزن بیشتری می دهد. یک روش برای رفع این مشکل این است که به هر کلمه متناسب با تعداد تکرار آن در کل سند امتیاز داده شود. این رویکرد امتیاز دهی Term Frequency-Inverse Document Frequency یا به اختصار TF-IDF گفته می شود. در این روش، Term Frequency به معنی امتیاز دهی تعداد کلمات در سند فعلی و Inverse Document Frequency به معنای امتیازدهی کم تکرار بودن کلمات در سند می باشد.
(تعداد کل کلمات)/(تعداد دفعات مشاهده کلمه)=TF
(تعداد اسنادی که کلمه در آن ها مشاهده شده)/(تعداد اسناد)IDF=1+log
وزن TF-IDF ، وزنی است که اغلب در بازیابی اطلاعات و استخراج متن مورد استفاده قرار می گیرد. این وزن یک معیار آماری است که برای ارزیابی اهمیت کلمه در یک اسندیا مجموعه.
مثال:
سندی را در نظر بگیرید که شامل ١٠٠ کلمه است و در آن کلمه تلفن” ۵ بار تکرار شده است. TF برای این کلمه 5/100 است. حال ، فرض کنید ما ١٠ میلیون سند داریم و کلمه تلفن در هزار مورد از آنها تکرار شده است. آنگاه IDF برابر خواهد بود با: log (10،000،000 / 1،000) = 4 . بنابراین TF-IDF 0.2 می باشد.
حال ما یک دید کلی از NLP داریم، وقت آن رسیده که شروع به ساخت چت بات کنیم. عنوان چت بات را ROBO فرض می کنیم.
import nltk
import numpy as np
import random
import string # to process standard python strings
به عنوان مثال، ما از صفحه ویکی پدیا به عنوان مجموعه نوشته برای چت بات خود استفاده خواهیم کرد. محتویات را از صفحه کپی کرده و آن را در یک پرونده متنی بنام chatbot.txt” قرار دهید. با این حال، شما می توانید از هر مجموعه نوشته دلخواه دیگر استفاده کنید. ما در فایل corpus.txt کل مجموعه را به لیست جملات و کلمات برای پیش پردازش بیشتر تبدیل می کنیم.
f=open('chatbot.txt','r',errors = 'ignore')raw=f.read()raw=raw.lower()# converts to lowercasenltk.download('punkt') # first-time use only
nltk.download('wordnet') # first-time use onlysent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences
word_tokens = nltk.word_tokenize(raw)# converts to list of wordsمثالی از sent_tokens و word_tokens را ببینید:
sent_tokens[:2]
['a chatbot (also known as a talkbot, chatterbot, bot, im bot, interactive agent, or artificial conversational entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods.',
'such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the turing test.']word_tokens[:2]
['a', 'chatbot', '(', 'also', 'known']اکنون باید تابعی به نام LemTokens تعریف کنیم.
lemmer = nltk.stem.WordNetLemmatizer()
#WordNet is a semantically-oriented dictionary of English included in NLTK.def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))در مرحله بعد، ما باید عملکردی برای سلام توسط ربات تعریف کنیم، یعنی اگر کاربر سلام کرد، ربات پاسخ سلام را برگرداند. ELIZA از یک واژه ساده برای سلام استفاده می کند. ما در اینجا از همان مفهوم استفاده خواهیم کرد.
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)برای تولید پاسخ در چت بات برای سوالات ورودی از مفهوم تشابه سند استفاده می شود. بنابراین ما با وارد کردن ماژول های لازم شروع می کنیم.
از کتابخانه scikit Learn ، بردار Tfidf را وارد کنید تا مجموعه ای از اسناد خام را به ماتریسی از ویژگی های TF-IDF تبدیل کنید.
from sklearn.feature_extraction.text import TfidfVectorizer
همچنین ، ماژول cosine similarity را از کتابخانه یادگیری scikit وارد کنید.
from sklearn.metrics.pairwise import cosine_similarity
این مورد برای یافتن شباهت بین کلمات وارد شده توسط کاربر و کلمات موجود در مجموعه نوشته استفاده می شود.
ما یک پاسخ عملکردی را تعریف می کنیم که پرسش کاربر را برای یک یا چند کلمه کلیدی شناخته شده جستجو می کند و یکی از چندین پاسخ ممکن را ارائه می دهد. اگر ورودی مطابق با هر یک از کلمات کلیدی را پیدا نکرد، به عنوان مثال پاسخ می دهد: متاسفم! من متوجه منظور شما نمی شوم”
def response(user_response):
robo_response=''
sent_tokens.append(user_response) TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2] if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_responseسرانجام ، متنی را که می خواهیم ربات ما هنگام شروع و پایان مکالمه استفاده کند وارد می کنیم.
flag=True
print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!")while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("ROBO: You are welcome")
else:
if(greeting(user_response)!=None):
print("ROBO: "+greeting(user_response))
else:
print("ROBO: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("ROBO: Bye! take care")تقریبا تمام شد. ما اولین چت بات خود را در NLTK کدنویسی کرده ایم. اکنون بگذارید ببینیم که چگونه با انسان تعامل دارد:

اگرچه این یک ربات بسیار ساده است، اما راه خوبی برای ورود به NLP و آشنایی با چت بات است. این مثال به شما کمک می کند تا به طراحی و چالش های ایجاد چت بات بیاندیشید.

در این مقاله به نحوه تشخیص چراغ راهنمایی توسط دیپ لرنینگ می پردازیم،مدل ها را معرفی کرده و مشکلات را بررسی می کنیم.
آنچه در این نوشته خواهیم داشت
هدف از این چالش تشخیص چراغ راهنمایی در تصاویر گرفته شده توسط رانندگان با استفاده از اپلیکیشن Nexar بود. در هر تصویر داده شده، لازم بود طبقه بندی گر” چراغ راهنمایی را تشخیص داده و قرمز یا سبز بودن آن را مشخص کند. به طور خاص، فقط می بایست چراغ راهنمایی را در جهت رانندگی شناسایی کرد.
این چالش بر اساس شبکه های عصبی پیچشی است، روشی بسیار رایج که در تشخیص تصویر با شبکه های عصبی عمیق مورد استفاده قرار می گیرد. مدل های کوچکتر نمرات بالاتری کسب کردند. علاوه بر این، حداقل دقت لازم برای پیروزی ٩۵ درصد بود.
Nexar تعداد ١٨۶۵٩ تصویر دارای برچسب را به عنوان داده های آموزشی ارائه می داد. هر تصویر با یکی از سه کلاس: بدون چراغ راهنمایی، چراغ قرمز و چراغ سبز برچسب گذاری شده است.
برای آموزش مدل ها از Caffe استفاده کردم. دلیل اصلی که Caffe انتخاب شد به دلیل تنوع زیاد مدل های از قبل آموزش دیده آن بود.
برای تجزیه و تحلیل نتایج، بررسی داده ها از Python ، NumPy و Jupyter notebook استفاده شد.
از نمونه های GPU آمازون برای آموزش مدل ها استفاده شد.
طبقه بندی نهایی در مجموعه آزمون Nexar با اندازه مدل ٨۴/٧ مگابایت به دقت ٩۵/٩۴ درصد دست یافت.
فرایند دستیابی به دقت بالاتر شامل تعداد زیادی آزمون و خطاست. در پشت برخی از آن ها منطقی وجود داشت و بعضی دیگر فقط بر اساس حدس و گمان جلو رفتند.
با تلاش برای تنظیم دقیق (fine-tuning) مدلی که در ImageNet با معماری GoogLeNet از قبل آموزش داده شده بود، شروع کردیم. خیلی به دقت بالای ٩٠ درصد دست یافتیم!
اخیرا بیشتر شبکه های منتشر شده بسیار عمیق بوده و پارامترهای زیادی دارند. به نظر می رسید که SqueezeNet بسیار مناسب بوده و همچنین دارای یک مدل از قبل آموزش دیده شده در ImageNet بود.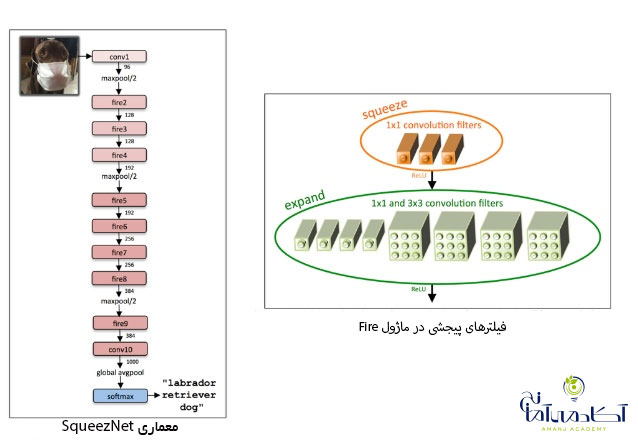
شبکه عصبی با استفاده از فیلترهای پیچشی یک در یک و بعضا سه در سه و همچنین با کاهش تعداد کانال های ورودی به فیلترهای سه در سه، می تواند خود را فشرده سازد.
بعد از مقداری سعی و خطا در تنظیم میزان یادگیری توانستیم مدل از قبل آموزش داده شده را با دقت ٩٢ درصد تنظیم کنیم.

بیشتر تصاویر مانند تصویر فوق افقی بودند، اما حدود ۴/٢ درصد عمودی بودند و بعضی از آن ها از بالا گرفته شده بودند.

اگرچه این بخش بزرگی از مجموعه داده ها نیست، اما می خواستیم مدل، آن ها را به درستی طبقه بندی کند.
متأسفانه ، هیچ داده ای در تصاویر jpeg که جهت گیری را مشخص می کند، وجود نداشت. به منظور تکمیل تصاویر از آموزش مدل در میانگین پیش بینی ها” در چرخش های ٠⁰ ، ٩٠⁰ ، ١٨٠⁰ و ٢٧٠⁰ استفاده کردیم. منظور از میانگین پیش بینی ها، میانگین احتمالات تولید شده توسط مدل در هر یک از این چرخش هاست.
در طول آموزش، شبکه SqueezeNet برای اولین بار به طور پیش فرض برش تصادفی تصاویر ورودی را انجام داد و ما آن را تغییر ندادیم. این نوع تقویت داده باعث می شود که شبکه بهتر تعمیم پیدا کند. به طور مشابه، هنگام تولید پیش بینی، چندین برش روی تصویر ورودی ایجاد کرده و میانگین نتایج را به دست آوردیم. از ۵ برش استفاده کردیم. ۴ برش از گوشه و ١ برش از مرکز ( با استفاده از کد Caffe).
چرخش و برش تصاویر پیشرفت بسیار کمی را نشان داد. از ٩٢ درصد به ۴۶/٩٢ درصد.
همه مدل ها بعد از یک نقطه خاص شروع به بیش برازش (overfit) کردند. این امر از طریق مشاهده صعود تنظیم اعتبار” در برخی نقاط قابل دستیابی است.
در این مرحله آموزش را متوقف می کنیم زیرا احتمالا مدل دیگر تعمیم نمی یابد. سعی کردیم آموزش را در نقطه ای که مدل شروع به بیش برازش با نرخ یادگیری ١٠ بار کمتر از سطح اصلی می کند، از سر بگیریم. این امر معمولا دقت را تا ۵/٠ درصد بهبود می بخشد.
در ابتدا داده های خود را به سه مجموعه تقسیم کردم: آموزش (۶۴٪) ، اعتبارسنجی (١۶٪) و آزمون (٢٠٪). بعد از گذشت چند روز به این نتیجه رسیدیم که صرف نظر کردن از ٣۶٪ از داده ها ممکن است خیلی زیاد باشد. در نتیجه مجموعه های آموزشی و اعتبار سنجی را با هم ادغام شده و از مجموعه آزمون برای بررسی نتایج استفاده شد.
هنگام تجزیه و تحلیل اشتباهات طبقه بندی گر در اعتبارسنجی ، متوجه اشتباهات فاحشی شدیم. به عنوان مثال، مدل با اطمینان می گفت چراغ سبز است در حالی که داده های آموزش می گفتند چراغ قرمز است. تصمیم گرفتیم این خطاها را در مجموعه آموزش برطرف کنیم. استدلال این بود که این اشتباهات باعث سردرگمی مدل می شوند و تعمیم آن را سخت تر می کنند. حتی اگر مجموعه آزمایش نهایی در پاسخ خود دارای خطای باشد، یک مدل عمومی تر شانس بیشتری برای دستیابی به دقت بالا در بین تصاویر دارد. در یکی از مدل های دارای اشتباه، ٧٠٩ تصویر را برچسب گذاری کردیم. این کار با Python script حدود یک ساعت زمان برد و تعداد خطاها را به ٣٣٧ عدد کاهش داد.
داده ها متعادل نبودند. ١٩ درصد از تصاویر بدون چراغ راهنمایی، ۵٣ درصد در چراغ قرمز و ٢٨ درصد در چراغ سبز بودند. ما سعی کردیم با بیش نمونه گیری ( oversampling) داده های کمتر متداول، مجموعه داده ها را متعادل کنیم؛ اما پیشرفتی حاصل نشد.
دریافتیم که تشخیص چراغ راهنمایی در روز و شب بسیار متفاوت است. فکر کردیم که شاید با جداسازی تصاویر روز و شب بتوانیم به مدل کمک کنیم. با در نظر گرفتن میانگین شدت پیکسل ها، جداسازی تصاویر روز و شب بسیار ساده بود. ما دو رویکرد را امتحان کردم که هیچ یک نتیجه بخش نبود:
آموزش دو مدل جداگانه برای تصاویر روز و تصاویر شب
آموزش شبکه برای پیش بینی ۶ کلاس به جای ٣ کلاس، با پیش بینی اینکه آیا روز است یا شب
٣٠ در صد از تصاویری که طبقه بندی گر برای آن ها از اطمینانی کمتر از ٩٧ درصد برخوردار بود انتخاب کردیم. سپس سعی کردیم طبقه بندی گر را فقط بر روی این تصاویر آموزش دهیم. اما بهبودی حاصل نشد.

احتمالاً وجود نقطه سبز در نخل که توسط تابش تشعشع بهوجود آمده باعث کی شود مدل به اشتباه چراغ سبز را پیش بینی کند.
 این مدل به جای چراغ سبز، چراغ قرمز را پیش بینی کرد. (وقتی بیش از یک چراغ راهنمایی در صحنه وجود دارد).
این مدل به جای چراغ سبز، چراغ قرمز را پیش بینی کرد. (وقتی بیش از یک چراغ راهنمایی در صحنه وجود دارد).

این مدل هیچ چراغ راهنمایی را تشخیص نداد در حالی که یک چراغ راهنمایی سبز در تصویر دیده می شود.

آنچه در این نوشته خواهیم داشت
یکی از ویژگی های بحث برانگیز آیفون X روش باز کردن قفل با استفاده از تشخیص چهره ( FaceID ) است که جایگزین TouchID شده است. اپل پس از ساخت تلفن بدون حاشیه، مجبور شد روش جدیدی را برای باز کردن قفل گوشی به شکلی آسان و سریع ایجاد کند. در حالی که برخی از رقبا به قرار دادن سنسور اثر انگشت در موقعیتی جدید بسنده کردند، اپل تصمیم گرفت در شیوه باز کردن تلفن روشی نوآورانه و انقلابی را ایجاد کند؛ یعنی نگاه کردن به صفحه نمایش گوشی! به لطف بهره گیری از یک دوربین جلوی پیشرفته و بسیار کوچک، آیفون X قادر به ایجاد نقشه سه بعدی از چهره کاربر است. علاوه بر این، تصویری از چهره کاربر با استفاده از یک دوربین مادون قرمز ضبط می شود که نسبت به تغییرات در نور و رنگ محیط پایداری بیشتری دارد. با استفاده از دیپ لرنینگ ، تلفن های هوشمند قادر هستند با جزئیات کامل تری چهره کاربر را ضبط کنند، بنابراین هر بار که تلفن توسط صاحب آن برداشته می شود او را تشخیص می دهند. در کمال تعجب، اپل اظهار داشته است که این روش حتی از TouchID نیز ایمن تر بوده و میزان خطای برجسته آن ١:١٠٠٠٠٠٠ است.
ما به نحوه ایجاد این فرآیند با استفاده از دیپ لرنینگ و چگونگی بهینه سازی هر مرحله تمرکز کردیم. در این مقاله، نشان می دهیم که چگونه الگوریتم شبیه به FaceID را می توان با استفاده از Keras پیاده سازی کرد. آزمایش های نهایی با استفاده از Kinect، یک دوربین RGB بسیار محبوب، که دارای خروجی بسیار مشابه دوربین های جلوی آیفون X است، انجام شده اند.
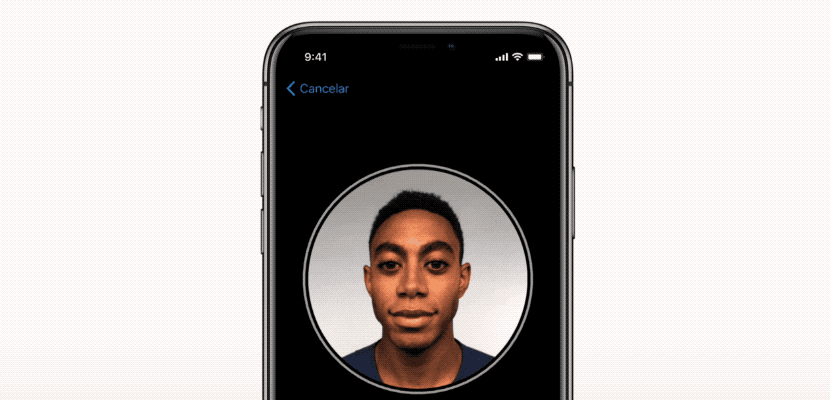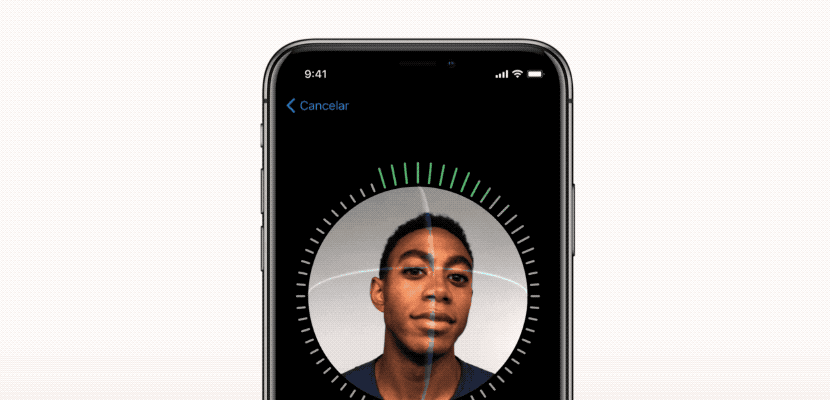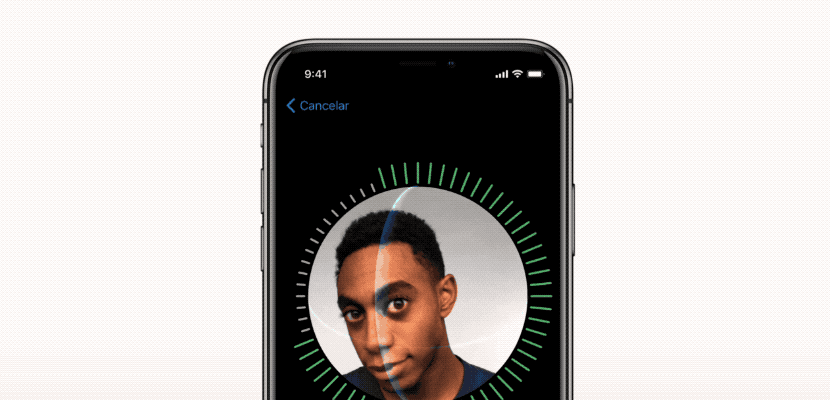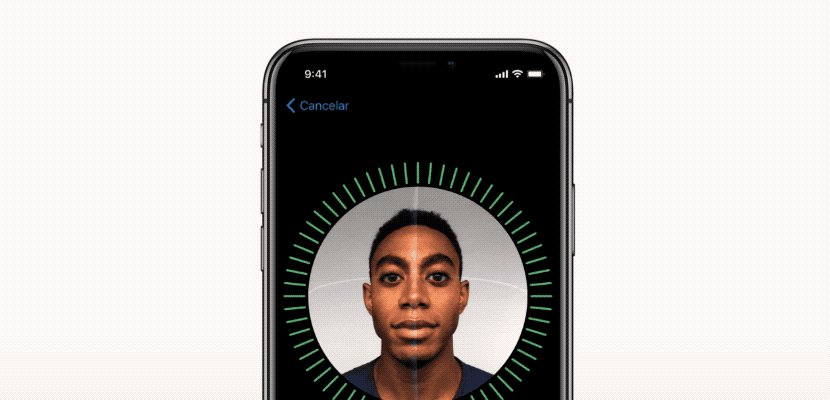
فرآیند تنظیم FaceID
شبکه های عصبی FaceID عملکرد پیچیده ای دارند. اولین قدم، تجزیه و تحلیل دقیق نحوه عملکرد FaceID در آیفون X است. در TouchID، کاربر مجبور است ابتدا با لمس مکرر حسگر، اثر انگشت خود را ثبت کند. پس از حدود ١۵ نمونه گیری مختلف، تلفن هوشمند فرایند ثبت را تکمیل کرده و TouchID آماده فعالیت خواهد بود. به طور مشابه در FaceID نیز کاربر باید صورت خود را ثبت کند. فرایند بسیار ساده است: کاربر فقط به گوشی نگاه می کند و سپس به آرامی سرش را به دنبال یک دایره می چرخاند. بنابراین صورت در حالت های مختلف ثبت می شود. حالا قفل صفحه نمایش آماده فعالیت است. این روش ثبت سریع و شگفت آور می تواند در مورد الگوریتم های یادگیری اساسی چیزهای زیادی به ما بگوید. به عنوان مثال، شبکه های عصبی در FaceID تنها عمل طبقه بندی را انجام نمی دهند. انجام طبقه بندی برای یک شبکه عصبی به معنای یادگیری این است که آیا شخصی که به آیفون نگاه می کند کاربر واقعی آن است یا خیر. بنابراین باید از برخی داده های آموزشی جهت پیش بینی درست” یا نادرست” استفاده کند. اما علی رغم موارد متعدد استفاده از دیپ لرنینگ ، در اینجا این رویکرد مؤثر نیست. ابتدا شبکه عصبی باید با استفاده از داده های جدید به دست آمده از چهره کاربر، آموزش ببیند. این امر نیازمند زمان، انرژی و داده های آموزشی از چهره های مختلف برای تشخیص تصویر است. بعلاوه، این روش امکان آموزش اپل در حالت آفلاین را فراهم نمی کند. اما FaceID با شبکه عصبی پیچشی Siamese (توضیح در بخش بعد) طراحی شده که در حالت آفلاین توسط اپل برای ثبت چهره آموزش می بیند.
یک شبکه عصبی Siamese اساسا از دو شبکه عصبی یکسان تشکیل شده است که تمامی وزن ها را نیز به اشتراک می گذارد. این معماری می تواند محاسبه فاصله بین نوع خاصی از داده ها مانند تصاویر را بیاموزد. به این صورت که داده از طریق شبکه Siamese منتقل شده و شبکه عصبی آن ها را در یک فضای n بعدی ترسیم می کند. سپس به شبکه آموزش داده می شود تا این ترسیم را تا زمانی که نقاط مختلف داده ها در طبقه بندی های مختلف تا حد ممکن به یکدیگر نزدیک شوند، ادامه دهد. در دراز مدت، شبکه یاد می گیرد که مهمترین ویژگی ها را از داده ها استخراج کرده و آن ها را در یک آرایه فشرده سازی کرده و یک ترسیم معنی دار ایجاد کند. برای درک درست این موضوع تصور کنید که چگونه نژادهای مختلف سگ ها را با استفاده از یک نمودار کوچک توصیف می کنید؟ به این صورت که سگ های مشابه، نمودارهای نزدیک تری دارند. احتمالا برای رمزگذاری رنگ سگ از یک عدد استفاده می کنید، برای مشخص کردن اندازه سگ از عددی دیگر، برای شکل گوش ها از عددی دیگر و غیره. به این ترتیب، سگ هایی که به یکدیگر شباهت دارند، نمودارهایی مشابه یکدیگر خواهند داشت. یک شبکه عصبی Siamese می تواند یاد بگیرد که این کار را برای شما انجام دهد، مشابه کاری که یک کدگذار خودکار انجام می دهد.
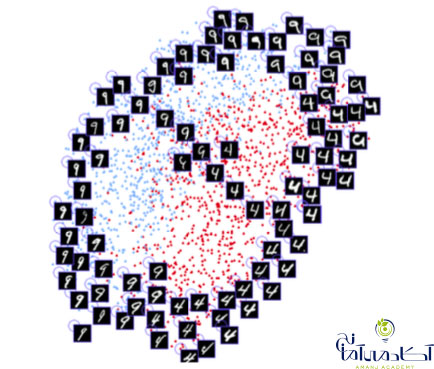
توجه کنید که معماری شبکه عصبی چگونه شباهت بین ارقام را یاد می گیرد و به طور خودکار آنها را در دو بعد دسته بندی می کند. تکنیک مشابهی روی صورت ها اعمال می شود.
با استفاده از این تکنیک می توان از تعداد زیادی چهره برای آموزش استفاده کرد تا تشخیص دهد که کدام چهره بیشترین شباهت را دارد. با داشتن بودجه کافی و قدرت محاسباتی (همانند اپل )، می توانید از مثال های سخت تری نیز استفاده کنید تا شبکه عصبی به مواردی همچون دوقلوها ، حملات خصمانه (ماسک) و غیره واکنش نشان دهد.
اینکه شبکه می تواند کاربران مختلف را بدون هیچ آموزش دیگری تشخیص داده و محاسبه کند که چهره کاربر، پس از گرفتن چند عکس در هنگام تنظیم اولیه، در نقشه نهفته چهره ها قرار دارد یا خیر. علاوه بر این ، FaceID قادر است با تغییرات در ظاهری شما سازگار شود : هم تغییرات ناگهانی (به عنوان مثال ، عینک ، کلاه ، آرایش) و هم تغییرات جزئی (مانند موهای صورت). این کار با اضافه کردن بردارهای چهره مرجع در این نقشه انجام می شود ، که بر اساس ظاهر جدید شما محاسبه می شود.

هنگامی که ظاهر شما تغییر می کند، FaceID سازگار می شود
در مورد همه پروژه های دیپ لرنینگ اولین چیزی که ما نیاز داریم داده است. ایجاد مجموعه داده های ما به زمان و همکاری بسیاری از افراد نیاز دارد و این می تواند بسیار چالش برانگیز باشد. به همین دلیل از مجموعه داده های چهره RGB-D موجود در اینترنت کمک گرفتیم. در این مجموعه داده، افراد با اشکال مختلف و جهات مختلف وجود دارند. همان طور که در هنگام استفاده از آیفون اتفاق می افتد.
در ابتدا یک شبکه عصبی پیچشی بر اساس معماری SqueezeNet ایجاد کردیم. شبکه عصبی به شکلی آموزش داده می شود که فاصله بین تصاویر یک شخص را به حداقل رسانده و فاصله بین تصاویر اشخاص مختلف را به حداکثر برساند. پس از آموزش ، شبکه قادر است چهره ها را در آرایه های ١٢٨ بعدی ترسیم کند. به گونه ای که تصاویر یک شخص در کنار هم طبقه بندی شده و از تصاویر افراد دیگر فاصله دارد. این بدان معنی است که برای باز کردن قفل، شبکه فقط باید فاصله بین تصاویر ذخیره شده در مرحله ثبت چهره و تصویری که در هنگام باز کردن قفل دریافت می کند، محاسبه کند. اگر فاصله زیر یک آستانه مشخص باشد، (هرچه کمتر باشد از امنیت بیشتری برخوردار است) قفل دستگاه باز می شود.
حال نحوه عمل این مدل را بررسی می کنیم. با شبیه سازی یک چرخه معمول FaceID. ابتدا ثبت چهره کاربر. سپس مرحله باز کردن قفل چه توسط کاربر (که باید موفقیت آمیز باشد) یا توسط افراد دیگرکه نباید قادر به باز کردن دستگاه باشند.
با ثبت چهره شروع می کنیم: یک سری عکس از یک شخص را از مجموعه داده گرفته و مرحله ثبت چهره را شبیه سازی می کنیم.

مرحله ثبت تصویر برای یک کاربر جدید با الهام از روند FaceID
حال ببینیم چه اتفاقی می افتد اگر همان کاربر سعی کند با حالت های مختلف چهره قفل دستگاه را باز کند.

فاصله صورت در فضای تعبیه شده برای همان کاربر
از طرف دیگر ، تصاویر RGBD از افراد مختلف به طور متوسط فاصله ١/١ را ایجاد می کند.

فاصله های چهره در فضای تعبیه شده برای کاربران مختلف
بنابراین، آستانه ای در حدود ۴/٠ باید برای جلوگیری از باز کردن قفل دستگاه توسط دیگران کافی باشد.
آموزش دیپ لرنینگ را در آکادمی آمانج تجربه کنید.
آنچه در این نوشته خواهیم داشت
در بازی های ویدئویی از کاربردهای مختلف هوش مصنوعی به روش های مختلف استفاده شده است. شروع استفاده از هوش مصنوعی در بازی های ویدئویی با آتاری آغاز شد؛ که یک نمونه کاملا ابتدایی در زمینه بازی های کامپیوتری محسوب می شود. اما امروزه شبکه های عصبی به سیستم های هوش مصنوعی اجازه می دهند تا هوشمندانه تر عمل کنند. بازی های ویدیویی فقط جنبه سرگرمی ندارند. آنها بستری را برای شبکه های عصبی فراهم می کنند تا یاد بگیرند که چگونه با محیط های پویا ارتباط برقرار کرده و مشکلات پیچیده را درست مثل زندگی واقعی حل کنند. بازی های ویدئویی طی چندین دهه برای ارزیابی عملکرد هوش مصنوعی مورد استفاده قرار گرفته اند.
استودیوهای ساخت بازی، میلیون ها دلار و هزاران ساعت را صرف توسعه طراحی گرافیک بازی ها می کنند که تا حد ممکن آن ها را به واقعیت نزدیک کنند. در حالی در چند سال گذشته، که این گرافیک ها به طرز شگفت آوری واقعی به نظر می رسند، اما همچنان تفکیک آنها از دنیای واقعی بسیار آسان است. با این حال، با پیشرفت های گسترده ای که در زمینه پردازش تصویر با استفاده از شبکه های عصبی عمیق صورت گرفته است، آیا زمان آن نرسیده که بتوانیم از این فناوری برای بهبود گرافیک استفاده کرده و همزمان نیاز انسانی برای ایجاد آنها را کاهش دهیم؟

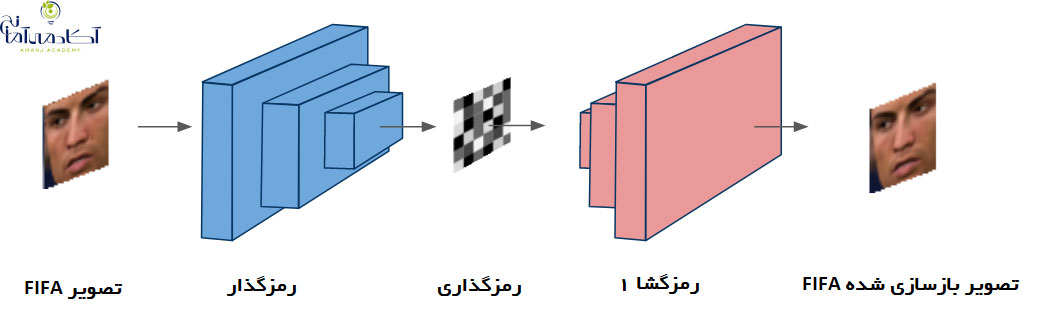
مقایسه چهره کریستیانو رونالدو، تصویر سمت چپ از FIFA و تصویر سمت راست تولید شده توسط یک شبکه عصبی عمیق.
برای اینکه دریابیم که آیا تحولات اخیر در یادگیری عمیق می تواند به سوال ما پاسخ دهد، با استفاده از الگوریتم معروف deepfakes ، روی بهبود چهره بازیکن ها در FIFA تمرکز می کنیم. Deepfakes یک شبکه عصبی عمیق است که می تواند برای تشخیص و تولید چهره های انسانی بسیار واقع بینانه آموزش ببیند. تمرکز ما در این پروژه بازآفرینی چهره بازیکن از درون بازی و بهبود آن هاست تا آنها را دقیقا مثل بازیکنان واقعی جلوه دهد. در اینجا توضیحی عالی در مورد چگونگی عملکرد الگوریتم deepfakes ارائه شده است. با استفاده از رمزگشای خودکار و شبکه های عصبی پیچشی، می توان چهره هر کسی را در یک فیلم با چهره افراد دیگر جابجا کرد.
اجازه دهید با نگاهی به یکی از بهترین چهره های طراحی شده در FIFA ، یعنی کریستیانو رونالدو، شروع کنیم و ببینیم آیا می توانیم آن را بهبود بخشیم؟ برای جمع آوری داده های مورد نیاز برای الگوریتم deepfakes، به سادگی چهره بازیکن را از گزینه پخش مجدد در بازی ضبط کردیم. حال می خواهیم این چهره را با چهره واقعی رونالدو جایگزین کنیم. به همین منظور، تعدادی از تصاویر رونالدو را از زوایای مختلف از گوگل دانلود کردیم. بر خلاف روش های استفاده شده توسط توسعه دهندگان بازی، در این روش می توان تمام داده های مورد نیاز را از جستجوی گوگل جمع آوری کرد؛ بدون اینکه لازم باشد رونالدو لباس مخصوص ضبط کردن تصاویر را به تن کند.

این الگوریتم شامل آموزش شبکه های عصبی عمیق به نام اتوکودرها است. این شبکه ها برای یادگیری بدون نظارت مورد استفاده قرار می گیرند و دارای یک رمزگذار هستند که می توانند با استفاده از یک رمزگذار، یک ورودی را رمزگذاری کنند. پس از آن، از یک رمزگشا برای بازسازی ورودی اصلی استفاده می کنند. برای تصویری مانند نمونه ما، از یک شبکه کانولوشن (پیچشی) به عنوان رمزگذار و یک شبکه دکانولوشن به عنوان رمزگشا استفاده می کنیم. این معماری به منظور به حداقل رساندن خطای بازسازی آموزش داده شده است. برای مورد ما، دو شبکه را به طور همزمان آموزش می دهیم. یک شبکه می آموزد چهره رونالدو را از گرافیک بازی FIFA بازآفرینی کند؛ و شبکه دیگر یاد می گیرد که چهره را از تصاویر واقعی رونالدو بازآفرینی کند. در deepfakes، هر دو شبکه، یک رمزگذار مشترک و دو رمزگشای مختلف استفاده می کنند. بنابراین، ما اکنون دو شبکه داریم که یاد گرفته اند که رونالدو در بازی و در زندگی واقعی چگونه به نظر می رسد.
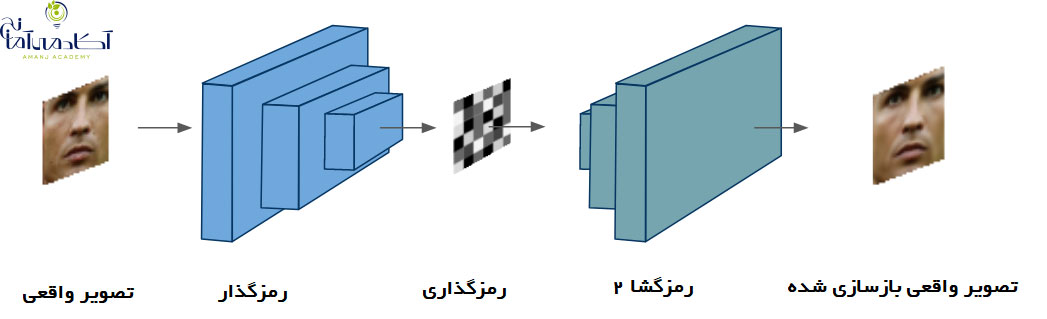
حالا نوبت بخش جذاب است. این الگوریتم با استفاده از یک ترفند هوشمندانه قادر به تغییر چهره هاست. در این مرحله، دومین شبکه رمزگشای خودکار با ورودی اولین شبکه تغذیه می شود. در واقع، رمزگذار اشتراکی، رمزگذاری را از تصویر FIFA گرفته، اما رمزگشا تصویر واقعی را بازسازی می کند.
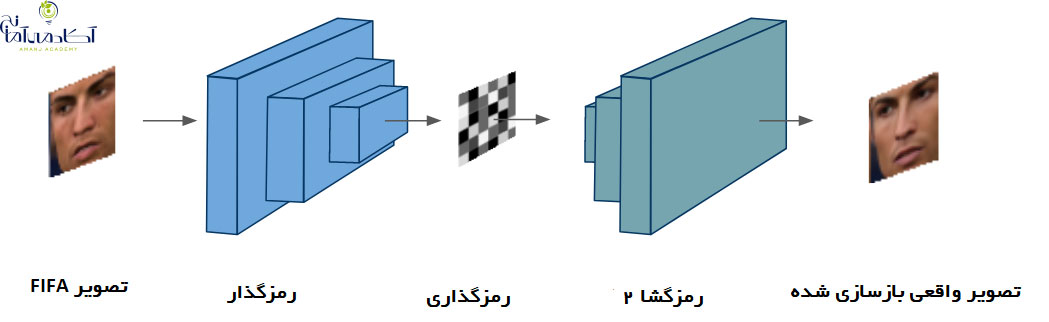
گیف زیر پیش نمایشی از نتایج حاصل از اجرای این الگوریتم را در چهره بازیکنان نشان می دهد.
 چهره های FIFA در مقایسه با تصاویر شبکه عصبی عمیق از رونالدو ، موراتا و اوزیل
چهره های FIFA در مقایسه با تصاویر شبکه عصبی عمیق از رونالدو ، موراتا و اوزیل
چه احساسی داشتید اگر می توانستید به جای الکس هانتر بازی کنید؟ تمام کاری که شما باید انجام دهید اینست که یک ویدیوی طولانی از خودتان بارگذاری کنید و مدل آموزش دیده را طی چند ساعت بارگیری کنید.
بزرگترین مزیت این روش، ایجاد چهره های شگفت انگیزی است که تفکیک آن ها از واقعیت دشوار است. همه این ها تنها با چند ساعت آموزش قابل دستیابی است. در حالی که طراحان بازی سال ها برای رسیدن به آن وقت صرف کرده اند. این بدان معناست که ناشران بازی می توانند بازی های جدید را بسیار سریعتر انتشار دهند. همچنین استودیوها می توانند میلیون ها دلار پس انداز کرده و موجودی خود را برای استخدام داستان نویس ماهر به کار گیرند. اما محدودیت بارز این است که این چهره ها در این روش مانند تصاویر تولید شده توسط رایانه برای فیلم ها (CGI) تولید می شوند، در حالی که بازی ها نیاز به تولید تصویر بی وقفه و در لحظه دارند. همچنین زمان مورد نیاز جهت تولید تصویر خروجی نیز در این روش زمان بر است.
با این وجود، یکی از مزایای بزرگ استفاده از دیپ لرنینگ در بازی های کامپیوتری در این است که پس از آموزش یک مدل، دیگر نیازی به مداخله انسانی برای ایجاد نتایج وجود ندارد.
در نتیجه اگر شخصی بدون داشتن تخصص گرافیکی بتواند تنها طی چند ساعت آموزش چنین فرایندی را عملی کند؛ قطعا توسعه دهندگان بازی ها می توانند با سرمایه گذاری در این راستا و به کارگیری افراد متخصص صنعت بازی ها کامپیوتری را متحول سازند.

برای اکثریت ما، مفاهیمی مانند یادگیری عمیق و هوش مصنوعی هنوز واژه هایی بیگانه هستند. بیشتر افرادی که برای اولین بار با این اصطلاحات مواجه شده اند با احساساتی ترکیب از تردید و ارعاب واکنش نشان می دهند. چگونه می توان به ماشین ها آموزش داد و آن ها را وادار به انجام کارهای انسانی کرد؟ چه چیزی رفتار انسان گونه ماشین ها را توجیه می کند؟
این ها سوالاتی مهم و بحث برانگیز در زمینه دیپ لرنینگ هستند. اما انسان همچنان قادر به پاسخ گویی و برطرف کردن تمامی تردیدهاست. به شرط آن که مایل به بررسی کاربردهای یادگیری عمیق و هوش مصنوعی در زندگی روزمره خود باشید. در این مقاله، ما نه کاربرد جالب دیپ لرنینگ و هوش مصنوعی را در زندگی روزانه بررسی می کنیم.
آنچه در این نوشته خواهیم داشت
یادگیری ماشین و یادگیری عمیق هر دو زیر مجموعه هوش مصنوعی هستند. اما یادگیری عمیق مرحله تکامل یافته و پیشرفته یادگیری ماشین است. در یادگیری ماشین، برنامه نویسان انسانی الگوریتم هایی را ایجاد می کنند که با استفاده از داده ها، تجزیه و تحلیل می کنند.
یادگیری عمیق با یادگیری ماشین متفاوت است زیرا در یک شبکه عصبی مصنوعی کار می کند که از مغز انسان الگو گرفته است. چنین ماشین هایی با ظرفیت یادگیری عمیق نیازی به پیروی ازدستورالعمل برنامه نویسان انسانی ندارند. در واقع دیپ لرنینگ از طریق حجم عظیم داده هایی که ما روزانه ایجاد می کنیم فعالیت می کند.
مدل های یادگیری عمیق در برخی جهات از هوش مصنوعی برتری دارند. برای مثال در بحث تشخیص تصویر، الگوریتم یادگیری عمیق دو برابر موثرتر از هر الگوریتم دیگر عمل می کنند.
فرض کنید یک مدل هوش مصنوعی به دقت ۵٠ درصد برسد. در این صورت این دستگاه برای استفاده مناسب نخواهد بود. برای مثال یک اتومبیل را در نظر بگیرید. یک فرد به اتومبیلی که ترمزش در ۵٠ درصد مواقع کار می کند اعتماد نمی کند. در حالی که اگر دقت مدل هوش مصنوعی سیستم به حدود ٩۵ درصد برسد برای استفاده عملی بسیار مطمئن تر خواهد بود. این سطح از دقت فقط با الگوریتم های یادگیری عمیق حاصل می شوند.
در ادامه به کاربردهایی که دیپ لرنینگ تا کنون در صنایع مختلف داشته است می پردازیم.

گیمرهای حرفه ای بطور مکرر با ماژول های دیپ لرنینگ در تعامل هستند. شبکه های عصبی عمیق قدرت تشخیص، طبقه بندی، ترمیم تصویر را دارا هستند. همچنین، آنها حتی قادر به تشخیص رقم های دست نویس در یک سیستم رایانه ای هستند. در راستای آموزش، یادگیری عمیق سوار بر شبکه عصبی فوق العاده ای می شود تا ماشین ها را قادر سازد از بینایی انسان تقلید کنند.

محققان Nvidia یک سیستم هوش مصنوعی ایجاد کرده اند که به روبات ها کمک می کند تا حرکات انسان را بیاموزند. امروزه روبات های خانه داری که اقداماتی را بر اساس ورودی های هوش مصنوعی از چندین منبع انجام می دهند، متداول هستند. همانند مغز انسان که وقایع را با توجه به تجربیات گذشته و احساسات آنالیز می کند؛ فرایندهای دیپ لرنینگ هم به روبات ها در انجام وظایف با توجه به عقاید هوش مصنوعی کمک می کند.
ترجمه های خودکار قبل از ظهور یادگیری عمیق نیز وجود داشته اند. اما یادگیری عمیق به ماشینها کمک می کند تا ترجمه ها را با دقت بالایی ارائه دهند؛ دقتی که در گذشته وجود نداشت. بعلاوه، یادگیری عمیق همچنین در ترجمه به دست آمده از تصاویر نیز کارآمد بوده است؛ فرایندی کاملاا جدید که با استفاده از تفسیر سنتی مبتنی بر متن امکان پذیر نبود.

بسیاری از مشاغل قبلا از یادگیری ماشین در زمینه تجربه مشتری استفاده کرده اند. به عنوان مثال می توان از پلتفرم های سلف سرویس آنلاین نام برد. بعلاوه، بسیاری از سازمان ها اکنون به یادگیری عمیق برای ایجاد گردش کار قابل اعتماد وابسته هستند. بیشتر ما قبلا با ربات های چت ( Chatbots) که توسط سازمان ها مورد استفاده قرار گرفته اند آشنا هستیم.
برای بهبود تجربه مشتری می توان از یادگیری عمیق برای تشخیص گفتار استفاده کرد. فناوری تشخیص گفتار مدت مدیدی است که وجود دارد ، اما تا رسیدن مدل های یادگیری عمیق ، تبدیل به یک محصول قابل فروش نمی شود.
نسل جدید کاربران مایلند با دستگاه و وسایل ارتباط برقرار کنند. به عنوان مثال siri اپل را در نظر بگیرید، که امکان فرمان صوتی و تشخیص صدا را نیز فراهم می کند. برقراری ارتباط با siri شبیه به تعامل با یک انسان است.
رابط کاربری Siri به ظاهر ساده به نظر می رسد. اما، الگوریتم های هوش مصنوعی طراحی شده در آن بسیار پیچیده هستند.
سیستم ها و دستگاه های اتوماسیون خانگی از طریق دستورهای صوتی کار می کنند. در این زمینه، یادگیری عمیق می تواند تجربه مشتری را به میزان قابل توجهی بهبود بخشد. با توجه به تکامل کاربردهای یادگیری عمیق می توان انتظار داشت پیشرفت های بیشتری را در این زمینه شاهد باشیم.

اگر به اندازه کافی خوش شانس بودید تا یک اتومبیل بدون راننده در حال حرکت را ببینید؛ بدانید که چندین مدل هوش مصنوعی به طور همزمان در آن در حال فعالیت هستند. بعضی مدل ها در شناسایی علائم رانندگی و بعضی در تشخیص عابرین پیاده مهارت دارند. بسیاری بر این عقیده هستند که اتومبیل های خودران ایمن تر از اتومبیل های دارای راننده عمل خواهند کرد.
در گذشته اضافه کردن رنگ به فیلم های سیاه و سفید یکی از وقت گیرترین شغل ها در تولید رسانه بود. اما به لطف مدل های یادگیری عمیق و هوش مصنوعی افزودن رنگ به عکسها و فیلمهای B/W، اکنون از همیشه راحت تر است.

یکی از بزرگترین شاهکارهای یادگیری عمیق امکان شناسایی تصاویر و تولید زیرنویس های هوشمند برای آنها است. در حقیقت تولید شرح تصاویر با استفاده از هوش مصنوعی به قدری دقیق است که بسیاری از انتشارات آنلاین در حال حاضر از این گونه تکنیک ها برای صرفه جویی در وقت و هزینه استفاده می کنند.
ماشین ها اکنون توانایی تولید متن جدید از ابتدا را دارند. آن ها می توانند نگارش، گرامر و سبک یک متن را یاد بگیرند و اخبار مؤثر را بنویسند. روبات های رومه نگاران که بر مدلهای یادگیری عمیق سوار شده اند؛ حداقل بیش از سه سال است که گزارش های دقیقی از مسابقات ارائه می دهند. و این مهارت منحصرا محدود به نوشتن گزارش نیست.
تولید متن مبتنی بر هوش مصنوعی تا حدی مجهز است که قادر به تحلیل بخش نظرات نیز می باشد. تا به امروز تولید متن در زمینه های مختلف، از مباحث مربوط به کودکان تا مقالات علمی، بسیار کارآمد بوده است.

در این زمینه، دستگاه های دیپ لرنینگ قادر به تشخیص لهجه های مختلف هستند. به عنوان مثال، ابتدا ماشین می تواند درک کند که فرد در حال صحبت به زبان انگلیسی است. سپس بر اساس گویش تمایز قائل می شود. بعد از تشخیص گویش، پردازش زبان توسط هوش مصنوعی دیگری که به آن زبان مسلط است انجام می شود. ناگفته نماند که در هیچ یک از این مراحل مداخله انسانی صورت نمی گیرد.
این موارد تنها چند نمونه از کاربردهای یادگیری عمیق بودند که تاکنون وجود دارند. یادگیری عمیق راهی را برای شرکت ها فراهم می کند تا ماژول های یادگیری را توسعه دهند. وقتی الگوریتم های پیچیده تر و غنی تری ایجاد شوند، شرکت ها قادر خواهند بود به رشد فزاینده دست یابند.

یادگیری عمیق با نتایج تجربی موفق و کاربردهای گسترده، پتانسیل تغییر آینده علم پزشکی را داراست. امروزه استفاده از هوش مصنوعی به طور فزاینده ای رایج شده است و در رشته های مختلفی همچون تشخیص سرطان مورد استفاده قرار می گیرد. یادگیری عمیق همچنین دید رایانه ای، تصویر برداری و تشخیص پزشکی دقیق تر را امکان پذیر می کند.
بنابراین تعجبی ندارد که در گزارشی از Report Linker اشاره شده است که انتظار می رود بازار هوش مصنوعی در صنعت پزشکی از ١/٢ میلیارد دلار در سال ٢٠١٨ به ٣۶ میلیارد دلار در سال ٢٠٢۵ برسد!! در این مقاله، پتانسیل یادگیری عمیق در صنعت مراقبت های بهداشتی و پزشکی و کاربردهای فراوان آن در این زمینه را بررسی می کنیم.
آنچه در این نوشته خواهیم داشت
از آنجا که یادگیری عمیق و هوش مصنوعی در صنعت محبوبیت فراوانی پیدا کرده اند، این سوال مطرح می شود که چگونه در چند سال آینده زندگی ما را تحت تاثیر قرار خواهند داد. در زمینه پزشکی، اگرچه ما طی چند سال اخیر تعداد زیادی از داده های بیماران را ضبط کرده ایم، اما تاکنون یادگیری عمیق بیشتر برای تجزیه و تحلیل داده ها از تصویر یا متن استفاده شده است. اما علاوه بر آن، به تازگی یادگیری عمیق برای پیش بینی طیف گسترده ای از مشکلات و نتایج بالینی نیز مورد استفاده قرار می گیرد. یادگیری عمیق آینده فوق العاده ای در زمینه پزشکی خواهد داشت.
علاقه امروز به دیپ لرنینگ در علم پزشکی از دو عامل ناشی می شود. اول، رشد تکنینک های یادگیری عمیق به طور گسترده. به ویژه روش های یادگیری بدون نظارت در حوزه هایی مانند فیس بوک و گوگل. دوم، افزایش چشمگیر داده های مراقبت بهداشتی
سیستم های سلامت الکترونیکی، داده های بیمار از قبیل اطلاعات دموگرافیک، سوابق پزشکی و نتایج آزمایش ها را ذخیره می کنند. این سیستم ها با استفاده از الگوریتم های یادگیری عمیق میزان تشخیص صحیح و مدت زمان لازم برای تشخیص بیماری را بهبود می بخشند. این الگوریتم ها از داده های ذخیره شده در سیستم های سلامت الکترونیک استفاده می کنند تا الگوهای روند سلامت و عوامل خطر را تشخیص داده و براساس الگوهای شناسایی شده، نتیجه بگیرند. همچنین محققان می توانند از داده های موجود در سیستم های سلامت الکترونیک در راستای ایجاد مدل هایی در یادگیری عمیق استفاده کنند که احتمال بروز برخی از نتایج مرتبط با سلامتی را پیش بینی می کند.
١. پیش بینی استاتیک
پیش بینی استاتیک، احتمال وقوع یک رویداد بر اساس مجموعه داده های محققان از سیستم طبقه بندی آماری بین المللی بیماری ها و مشکلات بهداشتی را بیان می کند. به عنوان مثال، Choi و همکارانش یک مدل را براساس داده های سیستم سلامت الکترونیک، از قبیل سوابق پزشکی و میزان مراجعه به بیمارستان بررسی کردند. براساس این اطلاعات، سیستم، احتمال بروز نارسایی قلبی را پیش بینی کرد.
٢. پیش بینی مبتنی بر مجموعه ای از ورودی ها
از داده های سیستم های سلامت الکترونیک برای پیش بینی بر اساس مجموعه ورودی ها استفاده می شود. می توان پیش بینی را با هر ورودی یا با کل مجموعه داده ها انجام داد. به عنوان مثال ، Choi و همکارانش، توسط این روش مدلی را توسعه داده اند. این مدل با استفاده از شبکه های عصبی مصنوعی زمان مراجعه بعدی به بیمارستان و دلیل مراجعه را پیش بینی می کند.
تکنیک های یادگیری عمیق از داده های ذخیره شده در سوابق سیستم های سلامت الکترونیک برای رفع بسیاری از نگرانی های مورد نیاز مراقبت های پزشکی ، مانند کاهش میزان تشخیص نادرست و پیش بینی نتیجه مراحل استفاده می کنند. با پردازش مقادیر زیادی از منابع مختلف مانند تصویربرداری پزشکی، شبکه های عصبی مصنوعی می توانند به پزشکان در تجزیه و تحلیل اطلاعات و تشخیص چندین بیماری کمک کنند:
• تجزیه و تحلیل نمونه خون
• بررسی سطح گلوکز در بیماران دیابتی
• تشخیص مشکلات قلبی
• تجزیه و تحلیل تصویر برای تشخیص تومورها
• تشخیص سلولهای سرطانی و تشخیص سرطان
• تشخیص آرتروز از MRI قبل از شروع آسیب

انکولوژیست ها سالهاست که از روشهای تصویربرداری پزشکی مانند توموگرافی کامپیوتری، تصویربرداری با رزونانس مغناطیسی و اشعه ایکس استفاده می کنند. در حالی که ثابت شده است که این سیستم ها برای بسیاری از انواع سرطان مؤثر هستند؛ تعداد زیادی از بیماران از سرطان هایی رنج می برند که با این دستگاه ها قابل تشخیص نیستند. شبکه های عصبی مانند شبکه های عصبی پیچشی، وعده های مربوط به آینده تشخیص سرطان را محقق می کنند. براساس همان تصاویر پزشکی، شبکه های عصبی مصنوعی می توانند سرطان را در مراحل اولیه با درصد خطای کمتر تشخیص داده و نتایج بهتری را برای بیماران فراهم کنند. به تازگی، دانشمندان موفق به آموزش مدل های مختلفی از یادگیری عمیق برای تشخیص انواع مختلف سرطان با دقت بالا شده اند.
در ادامه نمونه هایی از تحقیقات دانشمندان را بررسی می کنیم:
در سال ٢٠٠۶ هزینه بستری افرادی که به بیماری قابل پیش پیشگیری دچار شده بودند در آمریکا به ٣٠ میلیارد دلار رسید. نیمی از بیماران بستری شده از دو بیماری رنج می برند: مشکلات قلبی و دیابت. از دیپ لرنینگ می توان برای بهبود میزان تشخیص و مدت زمان لازم برای ایجاد پیش آگاهی استفاده کرد.این امر می تواند تعداد بستری شدگان را به شدت کاهش دهد.
برخی از تیم های تحقیقاتی در حال حاضر راه حل های خود را برای این مشکل به کار می گیرند.
در کشورهای در حال توسعه ، بیش از ۴١۵ میلیون نفر از نوعی نابینایی به نام رتینوپاتی دیابتی رنج می برند که از عوارض ناشی از دیابت است. یادگیری عمیق می تواند به جلوگیری از این بیماری کمک کند. یک مدل از شبکه های عصبی مصنوعی، می تواند با داده های گرفته شده از تصویربرداری شبکیه، تشخیص خونریزی، علائم اولیه و شاخص های رتینوپاتی دیابتی کار کند. بیماران دیابتی به دلیل تغییرات شدید سطح قند خون، به این عارضه دچار می شوند. این در حالی است که بیماران دیابتی را می توان از نظر سطح گلوکز کنترل کرد. یک مدل دیپ لرنینگ می تواند از این داده ها برای پیش بینی زمان افزایش و کاهش سطحح گلوکز خون بیماران استفاده کرده و به آن ها اجازه می دهد تا با خوردن یک میان وعده پر قند یا تزریق انسولین، عکس العمل نشان دهند.
بیش از ٣۶ میلیون نفر در سراسر جهان از ویروس نقص سیستم ایمنی بدن رنج می برند. این افراد برای درمان وضعیت خود نیاز به دریافت دوز روزانه داروهای ضد ویروس دارند. HIV می تواند به سرعت جهش یابد. بنابراین، برای ادامه درمان HIV، باید داروهای تجویز شده برای بیماران را تغییر دهیم. استفاده از یک الگوی یادگیری عمیق به نام یادگیری تقویتی می تواند به ما در مقابله با این نوع ویروس ها کمک کند. در این روش، مدل پیچشی می تواند بسیاری از نشانگرهای زیستی را با استفاده از هر دوز دارو ردیابی کرده و بهترین مسیر عملی را برای درمان مداوم فراهم کند.
تیمی از محققان در دانشگاه تورنتو ابزاری به نام DeepBind ایجاد کرده اند. طوری که یک مدل شبکه عصبی پیچشی که داده های ژنومی را می گیرد و توالی پروتئین های اتصال دهنده DNA و RNA را پیش بینی می کند. محققان می توانند از DeepBind برای ایجاد مدلهای رایانه ای استفاده کنند که اثرات تغییرات در توالی DNA را نشان دهد. آنها می توانند از این اطلاعات برای توسعه ابزارها و داروهای تشخیصی پیشرفته تر استفاده کنند.
با وجود مزایای بسیاری که استفاده از سیستم های سلامت الکترونیک به همراه دارند؛ همچنان ریسک هایی را نیز به دنبال خواهند داشت. داده های ذخیره شده در این سیستم ها حامل اطلاعات شخصی بیماران بوده که در بسیاری موارد افراد ترجیح می دهند این اطلاعات محرمانه باقی بمانند. بیمارستان ها همچنین داده های غیر پزشکی، مانند آدرس بیماران و اطلاعات کارت اعتباری آن ها را ذخیره می کنند؛ که این سیستم ها را به عنوان هدف اصلی برای حمله می کند. با وجود داده های حساس ذخیره شده در سیستم های سلامت الکترونیک و آسیب پذیری آن ها، محافظت از آن و حفظ حریم خصوصی بیماران بسیار مهم است.
تعجب آور نیست که در آینده نزدیک، شاهد باشیم که میانگین امید به زندگی” بشر ٢٠ سال افزایش یابد؛ و این امر میسر نخواهد شد مگر توسط تکنیک های هوش مصنوعی و یادگیری عمیق.

آیا ما به این بن بست در دنیای مدرن نرسیده ایم که باید دشمنان خود را دوست داشته باشیم؟
واکنش زنجیره ای نفرت و کینه باعث ایجاد نفرت می شود، جنگ هایی که جنگ های بیشتری را تولید می کنند باید درهم شکسته شوند، وگرنه ما در پرتگاه نابودی غرق خواهیم شد.
این جملات بخشی از سخنرانی به یادماندنی مارتین لوترکینگ فقید به اسم رویایی دارم» می باشد که در سال ۱۹۶۳ در گردهمایی بزرگ طرفداران تساوی حقوق سیاهان که دربرابر بنای یادبود آبراهام لینکلن در واشنگتن دیسی برگزار شد نطق شد، دکتر لوتر کینگ در این سخنرانی، که در آن عبارت رویایی دارم» تکرار میشد، درباره آرزوی خود سخن گفت و ابراز امیدواری کرد که زمانی آمریکا طبق مرام و آرمان خویش زندگی کند و تحقق مساوات و برابری ذاتی انسانها را به چشم ببیند.
این سخنرانی جز قوی ترین و تاثیرگذارترین سخنرانی های تاریخ آمریکا میباشد ، حال جدا از محتوای زیبا و مناسب جامعهی آمریکا ، چه چیزهایی مارتین لوترکینگ را به این درجه از قدرت در سخنوری رساند؟
در این مقاله من میخواهم ۸ نکته ی بسیار کاربردی که به شما کمک میکند سخنرانی و ارائه ای بی نظیر داشته باشید را معرفی کنم ، امیدوارم این مقاله برای همهی شما مفید واقع شود.
همه ی ما میدانیم که توانایی جلبکردن توجه دیگران هنگام صحبت با آنها، منافع زیادی به همراه دارد و کمک میکند تا در جلسات، مذاکره و یا مصاحبههای کاری ارتباط موثر برقرار کنید. با کسب مهارت در این زمینه، متقاعد کردن دیگران برای فهم منظور شما بسیار راحتتر خواهد بود. جذاب صحبت کردن، اعتبارتان را بالا میبرد و درهای پیشرفت شغلی را به رویتان میگشاید.
حال سوال پیش می آید که چگونه جذابتر حرف بزنیم؟ به کمک این تکنیکها میتوانید در گفتگوها و مذاکرات جذابتر حرف بزنید.
تصور کنید کسی جلویتان نشسته که به سختی حاضر است در چشمهای شما نگاه کند. شانههایش افتاده ، پشتش خمیده و حرکات بدنش هنگام صحبت نامناسب است، هیچ احساساتی در صورتش دیده نمیشود و یکنواختی از صدایش میبارد. حتی اگر موضوع صحبتش هم جذاب باشد، ظاهرش طوری نشان میدهد که حرف مهمی نمیزند.
آنوقت چه انتظاری از شما میرود که به حرفهایش توجه کنید؟زبان بدن شما خیلی بیشتر از کلماتتان با مخاطب حرف میزند. برای همین است که مطمئن به نظر رسیدن، علاقهمند جلوهکردن و مشتاقبودن در گفتگوها تا حد زیادی اهمیت دارد.
اولین چیزهایی که توجه مخاطبتان را به خود جلب میکند، مدل ایستادن، حالتهای چهره، تُن صدا، ژستها و حرکات اعضای بدنتان است. با صاف ایستادن به شنونده صحبتهایتان نشان دهید که اعتماد به نفس دارید. در چشمهایش نگاه کنید (ارتباط چشمی برقرار کنید)، لبخند زدن را فراموش نکنید و هنگام حرفزدن از حرکات دست بهطور هدفمند و سنجیده استفاده کنید.
آخرین باری را که مجذوب داستانی مسحورکننده شده بودید یادتان میآید؟
شاید رمان یا فیلمی بوده که نمیتوانستید دست از خواندن یا دیدن آن بردارید.
شاید هم ماجرایی بوده که کسی برایتان تعریف کرده است. داستان تعریفکردن برای مسحورکردنِ علاقه و تخیل افراد، حسابی مؤثر است. میتوانید برای شرحدادن این که چه کسی هستید و چرا اینجایید از آن استفاده کنید. میتوانید به کمک قصهها و ماجراها آموزش بدهید، ایجاد انگیزه کنید، رؤیایی را توصیف کنید یا همدلی نشان بدهید.
وقتی داستانی را تعریف میکنید، کاری کنید که شنوندهتان بتواند داستان را تجربه کند. جزئیات و ریزهکاریهایی به کار ببرید که همه پنجحس او را درگیر کند و به کمک زبان بدن و حرکات متناسب، تمام حواسش را جمع خودتان کنید.
میتوانید از استعارهها هم استفاده کنید تا بر مطلب، صحه بگذارید و موضوع بهتر برای مخاطبتان جا بیفتد. استعارهها به روایتتان جان میبخشند و به شنونده فرصت میدهند تا در ذهنش حرفتان را تفسیر کند. بخصوص اگر سعی میکنید مفاهیم پیچیدهای را توضیح بدهید، استعارهها میتوانند فهم قضیه را بسیار راحتتر کنند.
اگر مخاطب، دوست و یا همکار شما نتواند بفهمد که چه میگویید، فوری حوصلهاش سر میرود. جویده صحبتکردن، تندتند حرف زدن یا بیش از حد کند صحبتکردن، همگی جلوی ارتباطی را که میخواهید ایجاد کنید، میگیرد.
یک راه خوب برای بهتر کردن تلفظتان این است که جلوی آینه تمرین کنید. وقتی این کار را میکنید خوب به صورتتان دقت کنید. اگر واضح صحبت کنید لبها، فَک و زبانتان، همه باید در حال حرکت باشند. میتوانید پنج دقیقه در روز وقت بگذارید تا از روی کتابی با صدای بلند بخوانید .شاید در ابتدا کمی خسته کننده به نظر برسد ولی پس از مدتی مثل یک اثر مرکب توانایی شما در سخنرانی و صحبت کردن کاملا زیرورو میشود، من به شما تضمین میدهم.

هشت راه طلايی برای یک سخنرانی فوق العاده
سکوت پیامهای ناگفته بسیاری را منتقل میکند. معنای سکوت میتواند بسته به زمان، محتوا و زبان بدنی که استفاده میکنید، متفاوت باشد.
اگر کسی مدام حرف بزند و یک لحظه هم سکوت نکند، چه حسی به شما دست میدهد؟
بعضی آدمها هستند که حتی اگر ندانند چه بگویند، باز هم یک سری کلمه مثل اممم»، میدونی» و خووب…» دارند که یک جوری بالاخره وقفهها را پر کنند و به یک نحوی برای خودشان زمان بخرند.
این بیوقفه، حرفزدن میتواند نشانه نامنظمبودن افکار یا سطحی بودن حرفهایشان باشد. و لا غیر، اما چند درنگ حسابشده بر مخاطب تأثیر میگذارد و فکرتان را بهتر منتقل میکند.
سکوت شما فرصتی در اختیار شنوندگانتان میگذارد تا بتوانند حرفهایتان را هضم کنند و به عقیدهشان در باب ایده شما شکل بدهند. وقفههای کوتاه، سرعت مکالمه را کنترل میکنند.
بلندخواندن از روی کتاب اینجا هم به کارتان میآید. در حین خواندن میتوانید جا دادن وقفهها در بین جملات و واژهها را تمرین کنید. شمرده شمرده، نفس بکشید و عبارات کوتاه به کار ببرید. به جای اینکه، یک جمله بلند را یکنفس تا آخر بخوانید، ببینید کجای جمله درنگکردن معنا دارد و آنجا وقفهای بدهید.
بیشتر وقتها اضطراب درون انسان بهگونهای، خودش را در بیرون هم نشان میدهد. ممکن است صدایتان بلرزد یا کلا درنیاید.
شاید دستهایتان شروع کنند به لرزیدن، سراسیمه به نظر برسید و یا خیلی تندتر از معمول حرف بزنید، چون بدجوری استرس دارید یا نفس کم آوردهاید.
این نشانههای بدیهیِ اضطراب، بر نحوه برقراری ارتباطتان تأثیر دارند و در شکلگیریِ آن، مشکل ایجاد میکنند.
چند کار هست که کمک میکنند بر اعصاب خود مسلط شوید. قبل از هر چیز چند نفس عمیق بکشید تا ضربان قلبتان پایین بیاید. سپس، از تکنیکهای آرامش بخش مثل تمرکز کردن و تجسم استفاده کنید تا آرامش خود را بهدست بیاورید.
یک راه دیگر این است که لبخند بزنید و به چشمهای طرف مقابلتان نگاه کنید. مهم نیست او چه کسی است، همکار تازه وارد، مشتریِ بالقوه یا مصاحبهگر. یادتان بیاورید که این فرد هم کسی است مثل شما. تمرکز خود را روی این بگذارید که یک گفتگوی غیرتصنعی و خالصانه ایجاد کنید. با یادآوری مداوم حرفهایی که قرار است بگویید، حواس خودتان را پرت نکنید.
افراد به اصطلاح کاریزماتیک جسور و جذابند، الهامبخش و صمیمیاند و بهخاطر همینها دیگران دوست دارند به حرف هایشان گوش بدهند.
برای اینکه جذبهتان را افزایش دهید، به طرف مقابلتان توجه کنید. این یعنی دو جفت گوشِ دیگر هم قرض کنید و تماموکمال، حواستان پیش طرف مقابلتان باشد.
برقراری ارتباط، مثل یک خیابان دوطرفه است؛ نمیشود فقط حرف بزنید، گوشکردن هم یک بخش کار است و اتفاقا بخش مهمی از کار هم به حساب میآید. پس فعالانه گوش دادن را تمرین کنید و مهارتتان را افزایش دهید.
قدم بعدی، تمرین خودآگاهی و کارکردن روی هوش هیجانی است. این دو ویژگی کمک میکنند تا به هیجاناتی که تجربه میکنید، توجه داشته باشید و درک کنید که چگونه این عواطف بر اطرافیانتان تأثیر میگذارند، تلاش برای فهم دیدگاه مخاطبتان هم ضروری است. خالصانه به همصحبتتان، زندگی و تجاربش علاقه نشان بدهید.
اگر میخواهید وقتی حرف میزنید دیگران به شما توجه کنند، باید حرفتان برای آنها باورکردنی باشد. این یعنی باید از استراتژیهای درستی برای جمعآوری اطلاعات استفاده کنید تا دادههایی که بهعنوان پشتوانه حرفتان میآورید، قوی و قابل اعتماد باشند. هرجا که ممکن است، آمارهای متناسب با موضوع، صادقانه و بررسیشده ارائه کنید تا حرفتان معتبرتر باشد. آمارِ درست، باعث افزایش قدرت استدلال شما و جلب اعتماد مخاطب میشود. اگر هم اطلاعات دقیقی ندارید سکوت بهترین استراتژی میباشد . صحبت کردن بدون اطلاعات موجب سلب اعتماد دیگران به شما میشود.
تصور کنید در جلسهای هستید که وقتی کسی حرف میزند، هیچکس ساکت نیست و همه در حال صحبتاند. حالا اگر شما حرف مهمی برای گفتن داشته باشید، چطور باید مردم را وادار به شنیدن کنید؟
در درجه اول، اگر همه نشستهاند، شما بلند شوید. این حرکت فیزیکی به حاضران نشان میدهد که شما حرفی برای گفتن دارید.
راه دیگر این است که اول حرفهای نفر قبلی را خلاصه کنید. با این کار خودتان را در بحث جا میدهید و نفر قبلی هم میفهمد که شما به حرفهایش گوش دادهاید و بالاخره اینکه خلاصه کردن ایدههای قبلی، مقدمهای دستتان میدهد تا به کمک آن، طرحِ ایدههای خودتان را شروع کنید.
راهکارهایی که در این مقاله گفته شد،همراه با راه حل های عملی آن به شما کمک میکند، چه در سخنرانیهای کاریتان و چه در مصاحبههای شغلی و یا چه در قرارهای دوستانه تان جذابتر باشید و به آنچه میخواهید، راحتتر برسید.

طبق آخرین مطالعات آماری انجام شده در دوره پیش از فیلترینگ تلگرام، این شبکه اجتماعی به همراه اینستاگرام و واتساَپ دارای بیشترین فراوانی عضویت در بین ایرانیان بوده است.
در این میان حدود ۹۴.۵ درصد از تلگرام ۴۳.۱ درصد از اینستاگرام و ۲۴.۳ درصد از واتساپ به طور فعال استفاده کرده اند.
همین آمارها نشان میدهد که بازاریابی شبکه های اجتماعی از چه جایگاه بالا و مهمی برخوردار است و عدم حضور دراین فضا عملا رقابت را برای صاحبان کسب و کار بشدت سخت خواهد کرد.
اما من در این مقاله من قصد دارم از ۵ اشتباهات رایجی که در شبکه های اجتماعی توسط برند ها و کسب وکارهای مختلف انجام شده و یا خودم شخصا مرتکب آن شده ام صحبت کنم.
این مطلب را برای شما با گفتن یک داستان شروع میکنم ،
چندی پیش یکی از برند های تقریبا مطرح در بازار پوشاک شروع به فعالیت در ۱۲ شبکه ی اجتماعی کرد تا هیچ کاربر ایرانی را از دست ندهد و به نوعی هر کس هرجا بود بتواند تبلیغات و محصولات این برند را ببیند با این شعار که :
هر فضایی که کاربر ایرانی در آن فعال است ما هم باید باشیم!
نه تنها از خودتان بلکه اگر از یک دیجیتال مارکتر هم اسم ۱۲ شبکه ی اجتماعی را بپرسید شاید نتواند به شما پاسخ بدهد،
ما قرار نیست به عنوان برند ، استارت آپ و یا هر چیز دیگری در تمام ما میتوانیم با یک استراتژی قوی و درست در چند شبکه اجتماعی فعالیت متمرکز کرده و هزینه و زمان خود را در مسیرهای فرعی از بین نبریم.
برای مثال یک کسب و کار B2B یا یک فعالیت صنعتی میتواند در لینکدین و اینستاگرام فعالیت مستمر با بازدهی بالا داشته باشد ولی توییتر در ایران برای این سبک کسب و کارها اصلا مناسب نیست .
از صاحبین کسب و کارهای زیادی این جمله را که چون رقیب بیزینس ما در فلان شبکهی اجتماعی فعالیت میکند پس لازم است که ماهم در آن حضور داشته باشیم.در اینگونه موارد بنظرم بهترین راه حل این است که ابتدا کاربران خود را بشناسیم و از خود بپرسیم که:
• آیا مخاطب ما به فرض، در اینستاگرام فعالیت دارد؟
• آیا پیج رقیبمان را در اینستاگرام تحلیل کردهایم؟
• آیا ما میتوانیم محتوایی متناسب با فضای اینستاگرام تولید کنیم؟

من به شخصه خیلی از کسب و کارها را دیده ام که در چند شبکه اجتماعی فعال بوده و فقط یک نوع محتوا را در همه جا منتشر میکنند.
همیشه و همیشه باید این را در نظر داشت که کاربران در هر شبکه اجتماعی رفتار خاصی دارند و قرار نیست یک محتوا با یک فرم و شکل یکسان در تمامی فضاها منتشر کنیم.
هر فضایی لحن محتوایی خود را دارد و نمیتوان به یک شکل عمل کرد. این راهم باید در نظر بگیریم که اگر فرصت تولید محتوا برای هر شبکه اجتماعی را نداریم خیلی بهتر هست که اصلا به آن رسانه ورود نکنیم.
در یک جمله میتوان گفت که : هر شبکه اجتماعی، استراتژی خاص خود را دارد.
همیشه از خود بپرسیم اگر محتوای یکسان در تمامی فضاها تولید میکنیم، چه دلیلی وجود دارد که کاربران آنلاین در تمامی فضاها ما را دنبال کنند. بدنبال این باشید که انتظار کاربر از شما در آن فضا چیست و چطور میتوانید آن را محقق کنید.
بهترین حالت ممکن این است که برای همان تعداد محدود شبکه اجتماعی که در آن فعال هستید یک استراتژی محتوایی داشته باشید تا بتوانید به درستی آن را مدیریت کنید.بعد از مدتی خواهید فهمید که چه قدر نرخ تعامل یا همان engagement rate شما رشد خواهد کرد.
در شروع فعالیت در هر شبکه اجتماعی چندماهی زمان میبرد تا به ممبرها یا فالوئرهای مناسبی برسیم. متاسفانه در ایران کسب و کارها برای اینکه سریعتر به نتیجه برسند با فالوئر و ممبر فیک شروع میکنند. تعدادی فالوئر فیک خریداری میکنند تا با ۰ فالوئر شروع نکنند که مبادا پیجشان ظاهر بدی داشته باشد.
نه تنها شروع بلکه ادامه دادن نیز با فالوئر های فیک بشدت به شما ضربه خواهد زد چراکه الگوریتم های شبکه های اجتماعی بشدت قوی و هوشمند شده اند و به راحتی فعالیت غیر عادی شما را گزارش میکنند.
به علاوه داشتن فالوئر فیک خیانت به خودتان است چرا که مخاطب دارید ولی فروش نه! و این مقدمهی خوبی برای نا امیدی از ادامهی فعالیت است.
اشتباه دیگری که کارشناسان شبکه های اجتماعی و مدیران کسب و کار دارند انتشار حجم زیادی از محتوا در هفته و ماه میباشد.
امروزه اغلب الگوریتمهای جدید شبکه های اجتماعی مثل الگوریتم های اینستاگرام اولویت خود را به کیفیت محتوا و نرخ تعامل مخاطب با محتوا دادهاند پس ومی ندارد که هفت روز هفته در شبکه های اجتماعی فعال باشیم.بهتر است به این فکر کنیم که چگونه میتوانیم پستهای متفاوت و محتواهای جذابی به روش های مختلف بگذاریم.
برنامه ریزی برای تولید محتوا ارزشمند تر از برنامه ریزی برای انتشار آن است چه برای سئو سایت چه برای رشد در شبکه های اجتماعی.

آیا میخواهید برنامه اندرویدی متناسب با کسب و کار خود را بسازید ، یا از طریق ساخت یک اپلیکیشن کاربردی کسب درامد کنید ؟
مطمئنا اگر به این موضوعات فکر کرده باشید برای شما این سوال پیش آمده که کدام زبان برنامه نویسی برای شما بهترین انتخاب است؟ در این مقاله به زبان هایی خواهم پرداخت که برای توسعه برنامه های اندرویدی قابل استفاده است.
اندروید بی شک رایج ترین سیستم عامل موبایلی در جهان است. اندروید توسط گوگل در اوت سال ۲۰۰۸ خریداری و توسعه داده شد. اندروید بر پایه ی لینوکس بوده و کاملا متن باز است، به این معنی که هر شرکت یا فردی میتواند آن را دانلود کرده و از آن برای محصولات خود استفاده کند. در اصل ، این سیستم عامل از طریق شرکت اندروید برای دوربینهای دیجیتال و موبایل طراحی شده بود اما در حال حاضر ، ۲.۳ میلیارد تلفن هوشمند اندروید در جهان وجود دارد! که این رقم بی شک بی نظیر است.
اندروید نه تنها از دو میلیارد تلفن هوشمند ، لپتاپ ، تبلت و کامپیوترهای شخصی پشتیبانی میکند ، بلکه اندروید قلب تپنده میلیاردها دستگاهی است که در زندگی روزمره خود از آنها استفاده میکنید. برخی از این وسایل عبارتند از: تلویزیون ، سیستمهای امنیت خانگی ، باکس های تلویزیونی ، دوربین ها ، ماشین ها ، سیستمهای ناوبری ، تبلت های هوشمند ، بازی رایانهای ، وسایل خانگی هوشمند و ….
حالا با این همه وجود نیاز به اندروید و زمینه کاری بسیار پر رونق آن به نظر شما چه زبان برنامه نویسی مناسب تر است ؟
در این مقاله من سعی دارم پنج مورد از بهترین و رایج ترین زبان های برنامه نویسی ، برای توسعه اندروید را به شما گفته و مزیت های هر کدام را برای شما بازگو کنم.
زبان جاوا محبوبترین زبان برنامهنویسی در این زمینه است. جاوا یک زبان برنامهنویسی استاتیک ، همه منظوره و متن باز است. جاوا از زمان راهاندازی سیستمعامل اندروید , زبان برنامهنویسی اولیه این سیستم عامل بوده است . جاوا در سال ۱۹۹۵ توسط James Gosling ساخته شد. این زبان برنامه نویسی در حال حاضر متعلق به اوراکل است.
جاوا براساس ++c ساخته شد تا یادگیری آن برای توسعه دهندگان ساده باشد. این زبان همراه با ++c بهترین زبانهای برنامهنویسی برای دانشجویان و افراد تازه کار برای یادگیری اصول برنامهنویسی هستند. زبان جاوا توسط بسیاری از دانشگاهها به عنوان اولین زبان برنامهنویسی برای آموزش به دانشجویان استفاده میشود.
برخلاف زبان های سوئیفت، سی شارپ و کاتلین ممکن است جاوا زبان برنامهنویسی مدرنی نباشد و مانند زبان های دیگر مدام بروزرسانی نشود. با این حال , زبان جاوا نقطه شروعی را برای توسعه دهندگان جدید مشخص میکند. یادگیری زبان جاوا در مقایسه با کاتلین بسیار سادهتر است. اگر یک توسعه دهنده تازه کار هستید و میخواهید توسعه اندروید را یاد بگیرید , جاوا یکی از آسانترین راهها برای شروع است.پس بهتر است از آن غافل نشوید.
زبان #C توسط مایکروسافت در سال ۲۰۰۰ ایجاد شد. سی شارپ یک زبان برنامهنویسی ساده ، انعطافپذیر ، ایمن ، و متن باز بوده و یکی از پراستفاده ترین زبانهای برنامهنویسی حال حاضردر جهان است. سی شارپ به توسعهدهندگان اجازه میدهد تا تمام برنامههای کاربردی از قبیل ویندوز ، کنسولها ، برنامههای وب ، برنامههای موبایل ، و سیستمهای backend را بسازند.
برنامه نویسان سی شارپ میتوانند برنامههای کاربردی ios و اندروید را با کمک Xamarin بسازند . Xamarin به عنوان بخشی از ویژوال استودیو ابزاری است که به توسعه دهندگان اجازه میدهد کدهای سی شارپ خود را به برنامه های بومی اندروید و یا ios تبدیل کنند. سی شارپ طراحان را قادر میسازد که برنامههای کاربردی ios بومی و اندروید را بدون آگاهی از یک زبان برنامهنویسی جدید بسازند.

پایتون یکی از رایجترین زبانهای برنامهنویسی زمانه اخیر است. پایتون که توسط Guido van Rossum در سال ۱۹۹۱ ایجاد شد. این زبان متن باز ، سطح بالا(ازین نظرکه به زبان انسان نزدیک است) ، پیشرفته و همه منظوره است.
پایتون یک زبان برنامهنویسی پویا است که از پارادایمهای توسعه شی گرا ، تابعی و رویهای پشتیبانی میکند. این زبان در برنامهنویسی یادگیری ماشین بسیار محبوب است. در توسعه نرمافزار های اندروید ، پایتون جهت ایجاد کتابخانهها ، توابع ، و دیگر وظایف پردازش به کار میرود .و جدا از موضوع مقاله که در مورد برنامه نویسی اندروید میباشد به نظر من بهترین زبان برنامه نویسی حال حاضر دنیاست.
کاتلین یک زبان برنامهنویسی مدرن , دقیق , ایمن , شی گرا و سازگار با همه ی پلتفرم هاست که توسط یک شرکت نرمافزاری به نام JetBrains در سال ۲۰۱۱ ساخته شدهاست. این زبان برای ساخت نرمافزارهای کاربردی , برنامه های اندروید و برنامههای بومی استفاده میشود. در حال حاضر گوگل توسط شرکت گوگل پشتیبانی میشود.
زبان کاتلین از زمان انتشار Android Studio 3.0 در اکتبر سال ۲۰۱۷ به عنوان زبان برنامهنویسی رسمی برای اندروید استفاده شدهاست. این زبان برای طراحی برنامههای کاربردی ، ساخت اپلیکیشن های مدرن و ارائه قابلیتهای جدید برای توسعه دهندگان طراحی شده است. کاتلین برای شما سادگی , انعطافپذیری و بهرهوری را فراهم می آورد.
کد های نوشته شده در این زبان نسبت به زبان جاوا کوتاه تر و تمیز تر است. برای پروژ های اندروید شدیدا ً توصیه میکنم که از این زبان استفاده کنید .
++C یکی از قدیمیترین و محبوبترین زبانهای برنامهنویسی است. ++C این زبان برای ساختن رابط های کاربری یا صفحات برنامه استفاده نمیشود ودر فرآیند توسعه اندروید ، ++C برای ساختن API ها و وظایف backend استفاده میشود. توسعه دهندگان front end درگیر توسعه ++C نیستند ، بلکه کارکرد این زبان بیشتر مربوط به API هاست که مربوط به بخش back-end است. کتابخانه های معروفی در + +C وجود دارند که برای توسعه دهندگان Android در دسترس هستند و میتوانند از آنها در برنامه های خود استفاده کنند.
اندروید رایجترین سیستمعامل در دنیا است. برای ساخت اپلیکیشن اندروید از دو زبان برنامهنویسی اصلی یعنی جاوا و کاتلین استفاده شدهاست. در حالی که زبان برنامهنویسی جاوا یک زبان برنامهنویسی قدیمی است اما زبان کاتلین یک زبان سریع واضح و در حال تکامل است. اگر شما یک توسعه دهنده جدید هستید و به تازگی میخواهید توسعه برنامه های اندرویدی را شروع کنید، پیشنهاد من به شما زبان کاتلین است.


درباره این سایت